|
I am a PhD candidate at Stanford University advised by Prof. Shuran Song. My B.S. and M.S. are from UC Berkeley, where I was fortunate to work with Prof. Pieter Abbeel at Berkeley AI Research (BAIR). I'm broadly interested in AI for robotics: data-driven approaches that enable embodied systems to perceive, reason, and make sequential decisions in the real world. |

|
|
|
|
Zhao Mandi, Changhao Wang, Xavi Puig, Joanne Truong, Haozhi Qi, Shuran Song Coming soon. |
|
|
Zhao Mandi, Yifan Hou, Dieter Fox, Yashraj Narang, Ajay Mandlekar*, Shuran Song* International Conference on Machine Learning (ICML), 2026 [arXiv] [Project Website] We study the problem of functional retargeting: learning dexterous manipulation policies to track object states from human hand-object demonstrations. We focus on long-horizon, bimanual tasks with articulated objects, which is challenging due to large action space, spatiotemporal discontinuities, and embodiment gap between human and robot hands. We propose DexMachina, a novel curriculum-based algorithm: the key idea is to use virtual object controllers with decaying strength: an object is first driven automatically towards its target states, such that the policy can gradually learn to take over under motion and contact guidance. |
|
|
Zhao Mandi, Yijia Weng, Dominik Bauer, Shuran Song International Conference on Learning Representations (ICLR), 2025 [arXiv] [Project Website] We present a novel approach to reconstructing articulated objects via code generation. By leveraging pre-trained vision and language models, our approach scales elegantly with the number of articulated parts, and generalizes from synthetic training data to real world objects in unstructured environments. |
|
|
Zoey Chen*, Zhao Mandi*, Homanga Bharadhwaj*, Mohit Sharma, Shuran Song, Abhishek Gupta, Vikash Kumar International Journal of Robotics Research (IJRR), 2024 [arXiv] We posit that image-text generative models, which are pre-trained on large corpora of web-scraped data, can serve as such a data source. These generative models encompass a broad range of real-world scenarios beyond a robot's direct experience and can synthesize novel synthetic experiences that expose robotic agents to additional world priors aiding real-world generalization at no extra cost. |

|
Bardienus P. Duisterhof, Zhao Mandi, Yunchao Yao, Jia-Wei Liu, Mike Zheng Shou, Shuran Song, Jeffrey Ichnowski [arXiv] [Project Website] We achieve simultaneous 3D dense point tracking and dynamic novel view synthesis on highly deformable objects. Our method, MD-Splatting, builds on recent advances in Gaussian splatting and learns a deformation function to project a set of canonical Gaussians into metric space, and enforce physics-inspired regularization terms based on local rigidity, conservation of momentum, and isometry. |

|
Zhao Mandi, Shreeya Jain, Shuran Song IEEE International Conference on Robotics and Automation (ICRA), 2024. [arXiv] [Project Website] A novel approach to multi-robot collaboration that harnesses the power of pre-trained large language models (LLMs) for both high-level communication and low-level path planning. Robots are equipped with LLMs to discuss and collectively reason task strategies; then generate sub-task plans and task space waypoint paths, which are used by a multi-arm motion planner to accelerate trajectory planning. |

|
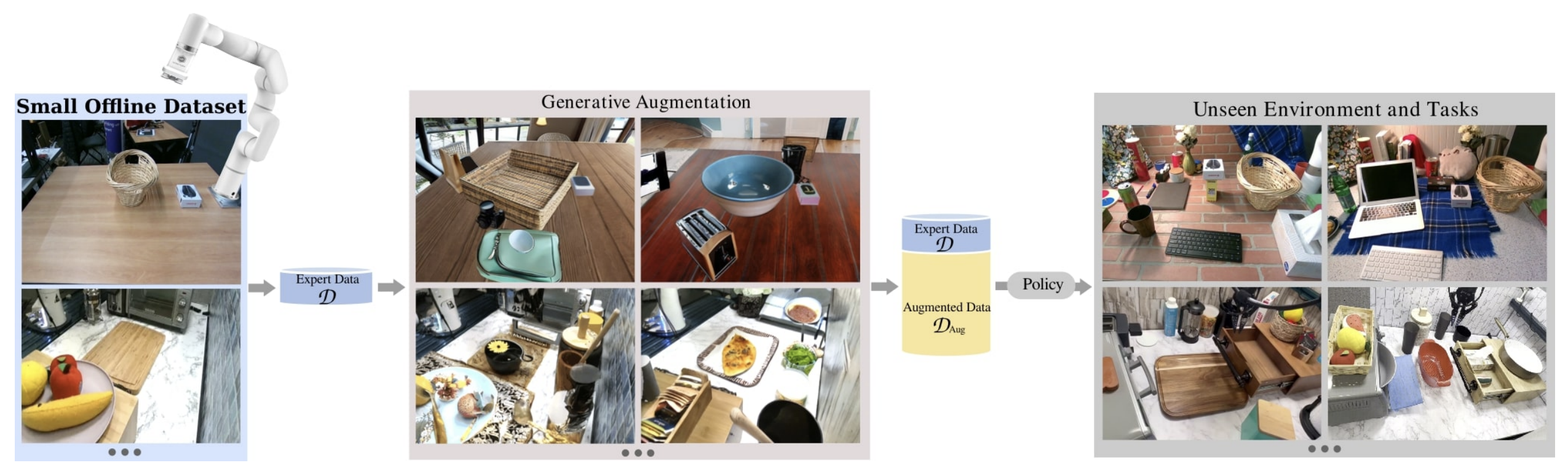
Zhao Mandi, Homanga Bharadhwaj, Vincent Moens, Shuran Song, Aravind Rajeswaran, Vikash Kumar [arXiv] [Project Website] A framework for multi-task, multi-scene robotic manipulation. It easily scales to many tasks, and uses recent advances in text2image generative models (e.g. stable-diffusion) to augment demonstration data with realistic visual variances. |
|
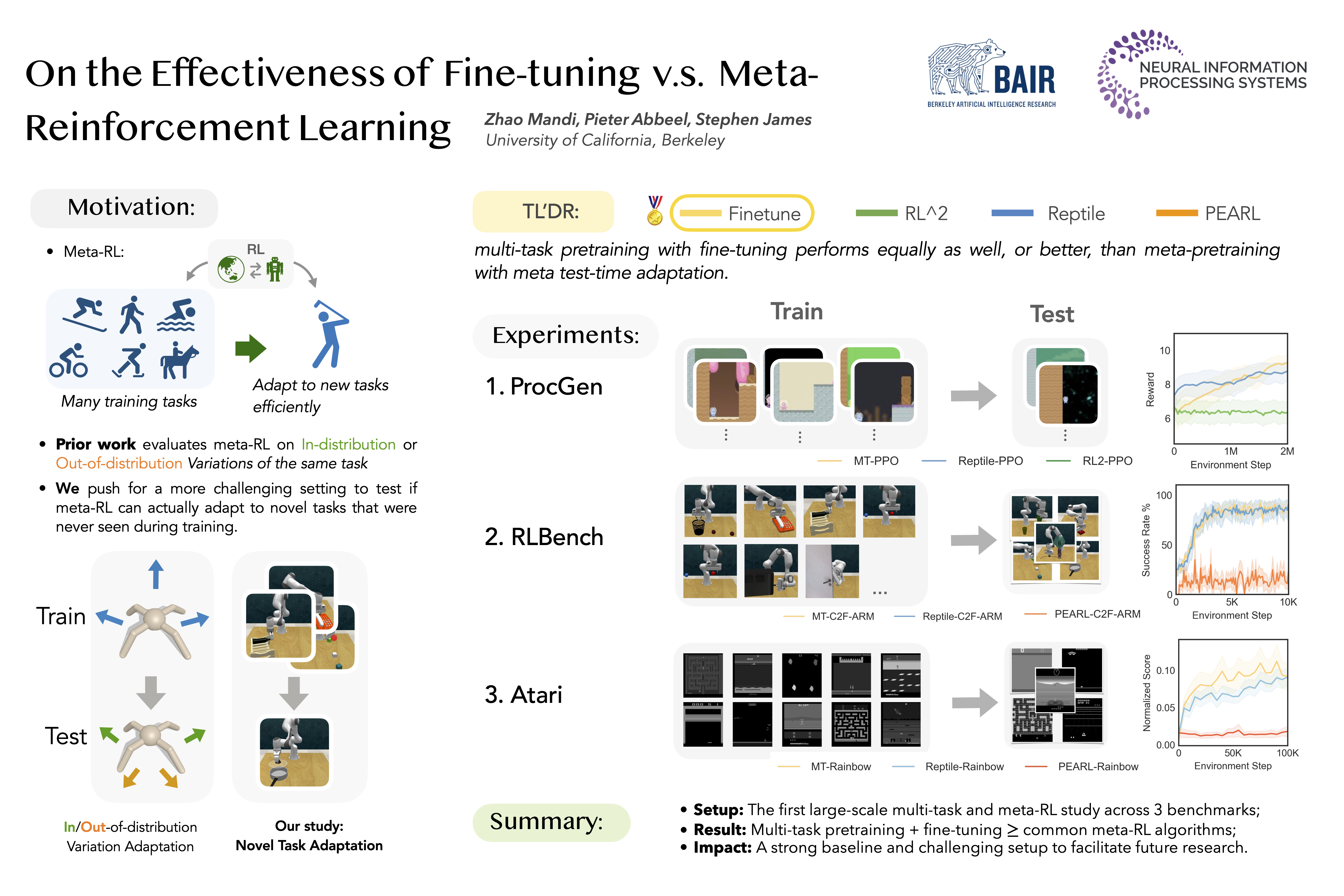
Zhao Mandi, Pieter Abbeel, Stephen James Thirty-Sixth Conference on Neural Information Processing Systems (NeurIPS), 2022 [arXiv] [Project Website and Code] We show that multi-task pretraining with fine-tuning can perform equally as well, or better, than meta-pretraining with meta test-time adaptation. We evaluate on a novel setting using vision-based RL benchmarks, including Procgen, RLBench, and Atari, where training is done across distinct tasks, and evaluations are made on completely novel tasks. |
|
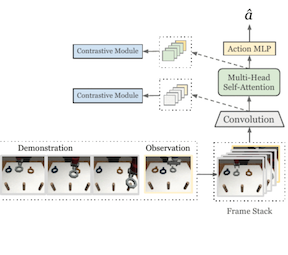
Zhao Mandi*, Fangchen Liu*, Kimin Lee, Pieter Abbeel IEEE International Conference on Robotics and Automation (ICRA), 2022. [arXiv] [Project Website and Code] We extend one-shot imitation learning to an ambitious multi-task setup, and support this formulation by a 7-task vision-based robotic manipulation benchmark. We propose our method, MOSAIC, that tackles challenges in multi-task one-shot imitation by improving network architecture and self-supervised representation learning. |
|
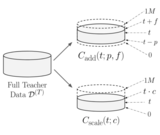
Daniel Seita, Abhinav Gopal, Zhao Mandi, John Canny Preprint, in submission, 2021. [arXiv] [Project Website and Code] We propose a conceptually simple way to manage a data curriculum to provide samples from a teacher to a student, and show that this facilitates learning in offline and mostly-offline RL. |

|
Daniel Seita, Chen Tang, Roshan Rao, David Chan, Mandi Zhao, John Canny Deep Reinforcement Learning Workshop at Neural Information Processing Systems (NeurIPS), December 2019. Vancouver, Canada. [arXiv] [Code] We investigate whether it makes sense to provide samples that are at a reasonable level of "difficulty" for a learner agent, and empirically test on the standard Atari 2600 benchmark. |
|
|
|
|